프롬프트가 막힐 때 꺼내보는 ‘맥락 주입’의 기술: LLM의 응답 품질을 결정짓는 3단계 전략

1. ‘모호함’을 제거하는 시스템 메타데이터의 힘 2. Few-Shot을 넘어선 ‘사례 기반 추론(CBR)’ 활용법 3. 정보의 과부하를 막는 ‘맥락 압축’ 전략 4. ‘비판적 검토’ 루프 강제하기 5. 도메인 지식의 동적 업데이트와 RAG의 조화 요약 및 결론
세상을 읽는 완벽한 지식 큐레이션
최신 언어 모델(GPT, Claude 등), 프롬프트 엔지니어링 및 논문 리뷰
1. ‘모호함’을 제거하는 시스템 메타데이터의 힘 2. Few-Shot을 넘어선 ‘사례 기반 추론(CBR)’ 활용법 3. 정보의 과부하를 막는 ‘맥락 압축’ 전략 4. ‘비판적 검토’ 루프 강제하기 5. 도메인 지식의 동적 업데이트와 RAG의 조화 요약 및 결론

거대 모델의 무거움, 비즈니스에는 독이 될 수 있어요 스승의 지혜를 제자에게, 지식 증류(Knowledge Distillation)의 마법 데이터의 해상도를 조절하는 양자화(Quantization) 전략 실전 워크플로우: 가벼우면서 강력한 AI 구축하기 하이브리드 전략: 클라우드와 로컬의 조화 요약 및 결론
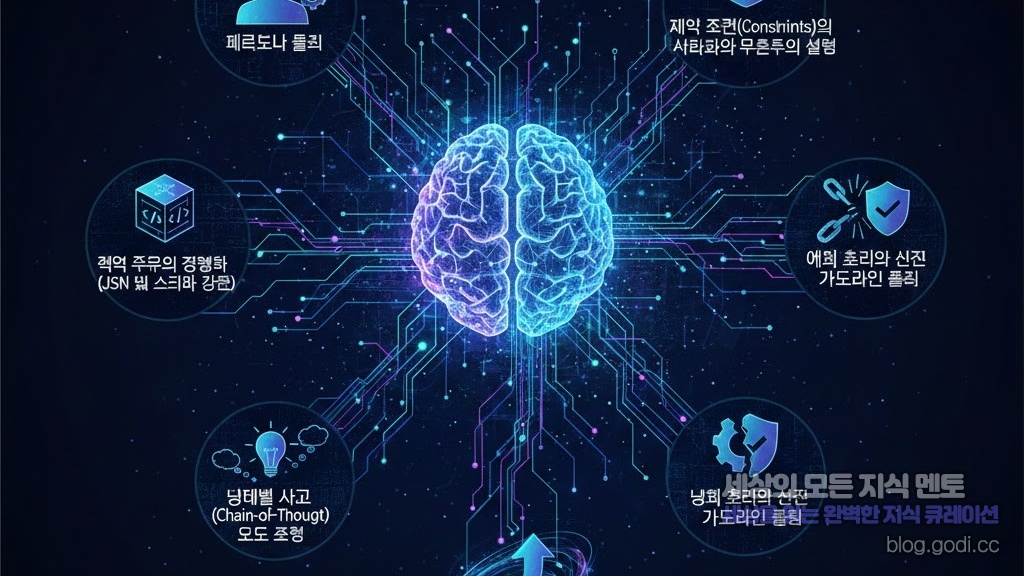
왜 시스템 프롬프트에 집중해야 할까요? 1. 페르소나 설계: 단순한 역할 부여를 넘어선 ‘전문성’ 주입 2. 제약 조건(Constraints)의 시각화와 우선순위 설정 3. 출력 구조의 정형화 (JSON 및 스키마 강제) 4. 예외 처리와 안전 가이드라인 설계 5. 단계별 사고(Chain-of-Thought) 유도 전략 결론: 지속적인 튜닝이 완성하는 최적의 사용자 경험

추론의 시대를 넘어, ‘검증’의 시대로 뉴로-심볼릭 아키텍처가 왜 지금 중요한가요? 실무에 적용하는 뉴로-심볼릭 설계 가이드 실제 적용 사례: 복잡한 기업 규제 준수(Compliance) 봇 개발자가 준비해야 할 ‘하이브리드’ 역량 마치며: 직관에 논리를 더하는 기술

텍스트라는 감옥에 갇힌 AI의 한계 세계 모델이란 무엇인가: 현실을 시뮬레이션하는 뇌 JEPA: ‘생성’하지 않고 ‘이해’하는 혁신 자율 주행과 로보틱스, 세계 모델의 실전 전시장 개발자가 준비해야 할 새로운 데이터 패러다임 결론: 언어를 넘어 실재(Reality)의 세계로

1. sLLM, 왜 지금 우리가 주목해야 할까요? 2. 성능은 유지하고 크기는 줄이는 마법, 양자화(Quantization) 3. 실전 전략: 우리만의 맞춤형 sLLM 구축 프로세스 4. sLLM 도입 시 반드시 체크해야 할 주의사항 결론: ‘적정 기술’로서의 AI가 가져올 미래

1. AI에게 ‘선함’과 ‘유용함’을 가르치는 법: 보상 모델의 역할 2. RLHF를 넘어선 새로운 흐름: DPO와 그 이상의 정렬 기술 3. ‘가드레일’ 이상의 가치: 안전한 AI 시스템 설계하기 4. 실무자를 위한 한 끗 차이: 정렬 데이터 큐레이션 5. 결론 및 요약: 우리는 어떤 AI를 만들 것인가?

1. ‘자기 성찰(Self-Correction)’이란 무엇일까요? 2. 왜 지금 ‘자기 성찰’에 주목해야 할까요? 3. 실무에 바로 적용하는 3단계 워크플로우 4. 주의할 점: ‘자기 성찰’의 함정 피하기 5. 결론 및 요약

💡 모델의 ‘인성’을 결정하는 정렬(Alignment)이란? 🧠 RLHF: 인간의 피드백으로 배우는 AI의 비결 🚀 2026년의 새로운 흐름: RLAIF와 Direct Preference 🛠 실무자를 위한 정렬 전략 가이드 ✅ 요약 및 결론

1. 모델이 크면 장땡? 이제는 ‘생각의 양’이 중요해요 2. AI의 뇌 구조를 바꾸는 ‘시스템 2 사고’ 3. 왜 지금 ‘추론 시간 확장’에 주목해야 할까요? 4. 실무자를 위한 ‘더 깊은 생각’ 유도 전략 마치며: AI와 함께 성장하는 법